O Google expandiu sua família de modelos Gemini com o lançamento do Incorporação de Gêmeos 2. Este modelo de segunda geração sucede ao modelo somente texto gemini-embedding-001 e foi projetado especificamente para enfrentar os desafios de armazenamento de alta dimensão e recuperação intermodal enfrentados pelos desenvolvedores de IA que constroem sistemas de nível de produção Geração Aumentada de Recuperação (RAG) sistemas. O Incorporação de Gêmeos 2 O lançamento marca uma mudança técnica significativa na forma como os modelos de incorporação são arquitetados, afastando-se dos pipelines específicos da modalidade em direção a um espaço latente unificado e nativamente multimodal.
Multimodalidade nativa e entradas intercaladas
O principal avanço arquitetônico no Gemini Embedding 2 é sua capacidade de mapear cinco tipos de mídia distintos –Texto, imagem, vídeo, áudio e PDF—em um espaço vetorial único e de alta dimensão. Isso elimina a necessidade de pipelines complexos que anteriormente exigiam modelos separados para diferentes tipos de dados, como CLIP para imagens e modelos baseados em BERT para texto.
O modelo suporta entradas intercaladaspermitindo que os desenvolvedores combinem diferentes modalidades em uma única solicitação de incorporação. Isto é particularmente relevante para casos de uso em que o texto por si só não fornece contexto suficiente. Os limites técnicos para esses insumos são definidos como:
- Texto: Até 8.192 tokens por solicitação.
- Imagens: Até 6 imagens (PNG, JPEG, WebP, HEIC/HEIF).
- Vídeo: Até 120 segundos de vídeo (MP4, MOV, etc.).
- Áudio: Até 80 segundos de áudio nativo (MP3, WAV, etc.) sem necessidade de uma etapa de transcrição separada.
- Documentos: Até 6 páginas de arquivos PDF.
Ao processar essas entradas nativamente, o Gemini Embedding 2 captura as relações semânticas entre um quadro visual em um vídeo e o diálogo falado em uma trilha de áudio, projetando-as como um único vetor que pode ser comparado com consultas de texto usando métricas de distância padrão como Similaridade de cosseno.
Eficiência via Aprendizagem de Representação Matryoshka (MRL)
Os custos de armazenamento e computação costumam ser os principais gargalos na pesquisa vetorial em grande escala. Para mitigar isso, o Gemini Embedding 2 implementa Aprendizagem de Representação Matryoshka (MRL).
Os modelos de incorporação padrão distribuem informações semânticas uniformemente em todas as dimensões. Se um desenvolvedor trunca um vetor de 3.072 dimensões para 768 dimensões, a precisão normalmente entra em colapso porque as informações são perdidas. Em contraste, o Gemini Embedding 2 é treinado para agrupar as informações semânticas mais críticas nas primeiras dimensões do vetor.
O modelo padrão é 3.072 dimensõesmas A equipe do Google otimizou três níveis específicos para uso em produção:
- 3.072: Precisão máxima para conjuntos de dados jurídicos, médicos ou técnicos complexos.
- 1.536: Um equilíbrio entre desempenho e eficiência de armazenamento.
- 768: Otimizado para recuperação de baixa latência e consumo de memória reduzido.
Aprendizagem de Representação Matryoshka (MRL) permite uma arquitetura de “lista restrita”. Um sistema pode realizar uma pesquisa grosseira e de alta velocidade em milhões de itens usando os subvetores de 768 dimensões e, em seguida, realizar uma reclassificação precisa dos principais resultados usando os embeddings completos de 3.072 dimensões. Isso reduz a sobrecarga computacional do estágio inicial de recuperação sem sacrificar a precisão final do pipeline RAG.
Benchmarking: MTEB e recuperação de contexto longo
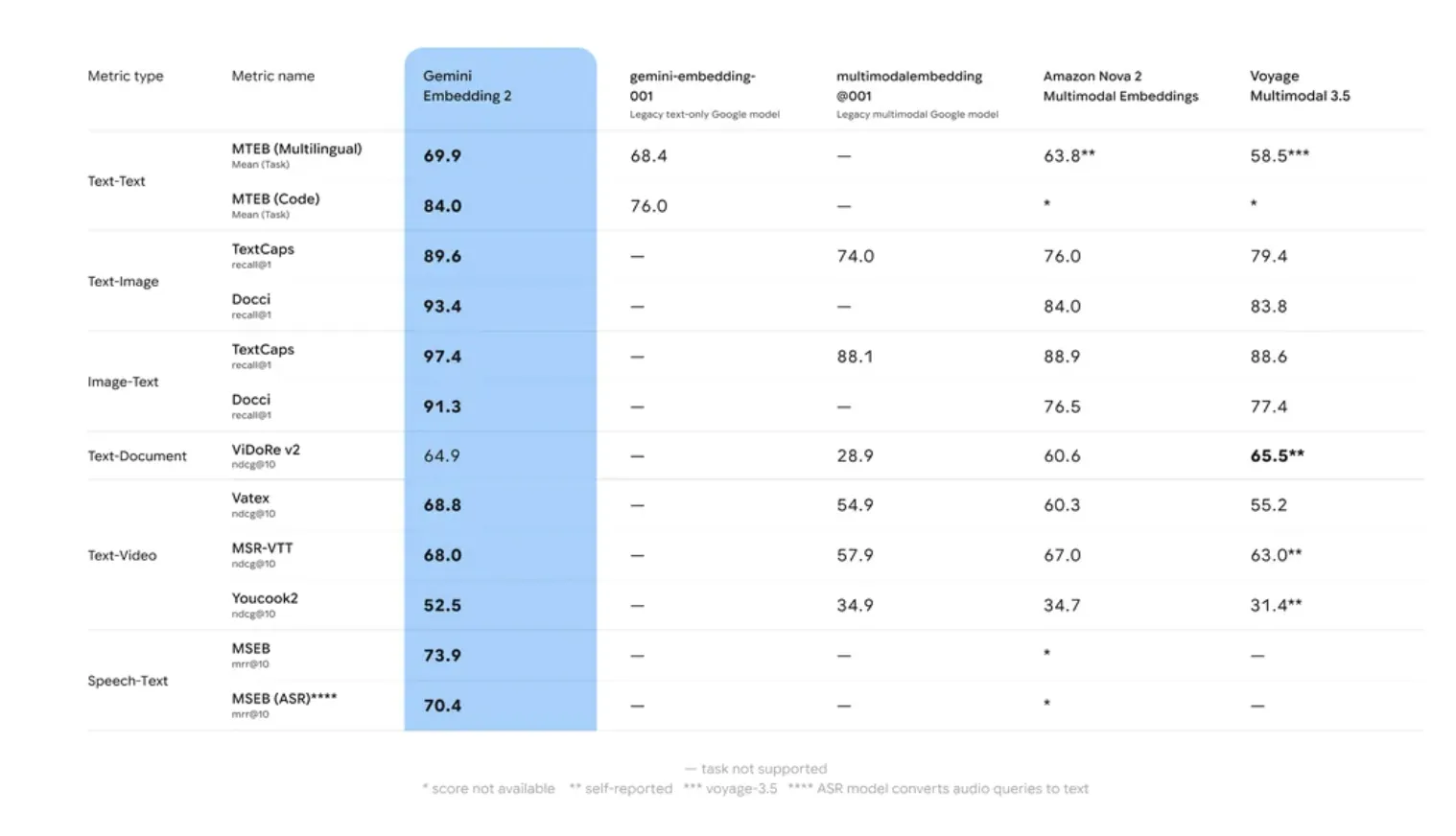
Avaliação interna e desempenho do Google AI no Referência de incorporação de texto massivo (MTEB) indicam que Gemini Embedding 2 supera seu antecessor em duas áreas específicas: Precisão de recuperação e Robustez para mudança de domínio.
Muitos modelos de incorporação sofrem de ‘desvio de domínio’, onde a precisão cai ao passar de dados de treinamento genéricos (como a Wikipedia) para domínios especializados (como bases de código proprietárias). O Gemini Embedding 2 utilizou um processo de treinamento em vários estágios envolvendo diversos conjuntos de dados para garantir maior desempenho de disparo zero em tarefas especializadas.
O modelo Janela de 8.192 tokens é uma especificação crítica para RAG. Ele permite a incorporação de “pedaços” maiores de texto, o que preserva o contexto necessário para resolver correferências e dependências de longo alcance dentro de um documento. Isto reduz a probabilidade de “fragmentação de contexto”, um problema comum em que um pedaço recuperado não possui as informações necessárias para que o LLM gere uma resposta coerente.
Principais conclusões
- Multimodalidade Nativa: Gemini Embedding 2 oferece suporte a cinco tipos de mídia distintos—Texto, imagem, vídeo, áudio e PDF—dentro de um espaço vetorial unificado. Isto permite entradas intercaladas (por exemplo, uma imagem combinada com uma legenda de texto) para ser processada como uma única incorporação sem pipelines de modelo separados.
- Aprendizagem de Representação Matryoshka (MRL): o modelo é arquitetado para armazenar as informações semânticas mais críticas nas primeiras dimensões de um vetor. Embora o padrão seja 3.072 dimensõesele suporta truncamento eficiente para 1.536 ou 768 dimensões com perda mínima de precisão, reduzindo custos de armazenamento e aumentando a velocidade de recuperação.
- Contexto e desempenho expandidos: O modelo apresenta um Janela de entrada de 8.192 tokenspermitindo ‘pedaços’ de texto maiores em pipelines RAG. Ele mostra melhorias significativas de desempenho no Referência de incorporação de texto massivo (MTEB)especificamente na precisão da recuperação e no tratamento de domínios especializados, como código ou documentação técnica.
- Otimização Específica de Tarefas: Os desenvolvedores podem usar
task_typeparâmetros (comoRETRIEVAL_QUERY,RETRIEVAL_DOCUMENTouCLASSIFICATION) para fornecer dicas ao modelo. Isto otimiza as propriedades matemáticas do vetor para a operação específica, melhorando a “taxa de acerto” na busca semântica.
Confira Detalhes técnicosem visualização pública por meio do API Gêmeos e Vértice AI. Além disso, sinta-se à vontade para nos seguir no Twitter e não se esqueça de participar do nosso SubReddit de 120k + ML e inscreva-se em nosso boletim informativo. Espere! você está no telegrama? agora você também pode se juntar a nós no telegrama.
A postagem Google AI apresenta Gemini Embedding 2: um modelo de incorporação multimodal que permite trazer texto, imagens, vídeo, áudio e documentos para o espaço de incorporação apareceu pela primeira vez no MarkTechPost.
Deseja saber mais sobre Inteligência Artificial, Clique Aqui!