A corrida para construir agentes autônomos de IA atingiu um enorme gargalo: os dados. Embora modelos de fronteira como Claude Code e Codex CLI tenham demonstrado proficiência impressionante em ambientes de terminal, as estratégias de treinamento e misturas de dados por trás deles permaneceram em segredos bem guardados. Esta falta de transparência forçou os investigadores e desenvolvedores a um ciclo dispendioso de tentativa e erro.
A NVIDIA agora está quebrando esse silêncio ao revelar uma estrutura abrangente para a construção de agentes terminais de alto desempenho. Ao apresentar Terminal-Tarefa-Gen e o Terminal-Corpus conjunto de dados, a NVIDIA está essencialmente dando à comunidade de desenvolvedores os planos para construir agentes que não apenas “conversam” sobre o código, mas que realmente o executam com precisão cirúrgica.
O problema da escassez de dados
O desafio de treinar um agente para a linha de comando é duplo. Primeiro, há uma escassez de recursos básicos – especificamente, diversos prompts de tarefas e os complexos arquivos de dependência necessários para criar ambientes realistas. Em segundo lugar, capturar “trajetórias” (as interações terminais passo a passo) é logisticamente doloroso. As interações humanas são lentas para serem registradas e a geração sintética por meio de agentes LLM é proibitivamente cara porque requer nova instanciação do ambiente Docker para cada turno.
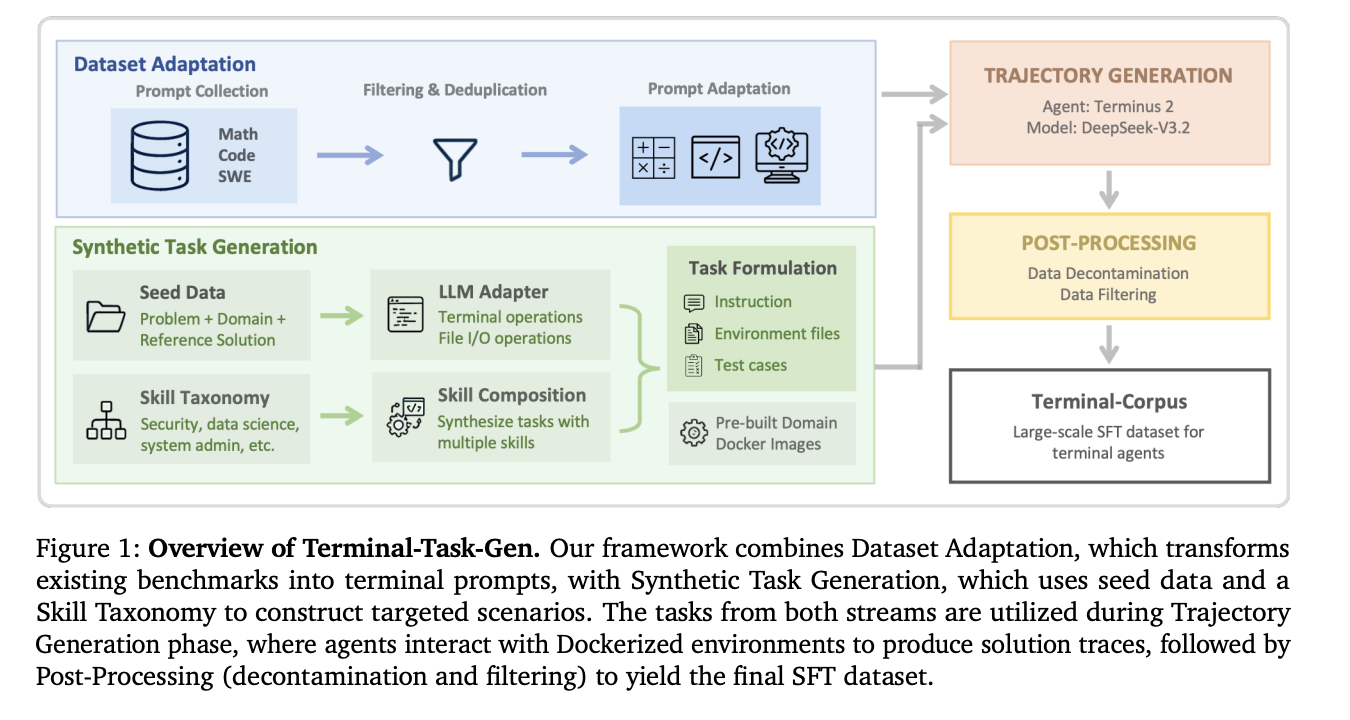
Terminal-Task-Gen: uma estratégia em duas frentes
A solução da NVIDIA é um pipeline de geração de dados “grosso a fino” chamado Terminal-Tarefa-Gen. Ele utiliza duas estratégias distintas para dimensionar dados de treinamento sem gastar muito.
1. Adaptação do conjunto de dados (a camada grosseira)
Em vez de começar do zero, a equipe aproveita conjuntos de dados existentes de alta qualidade de ajuste fino supervisionado (SFT) de domínios de matemática, código e engenharia de software (SWE).. Eles transformam esses prompts estáticos em tarefas terminais interativas.
- Matemática e código: Usando 163 mil prompts matemáticos e 35 mil prompts de código, eles envolvem esses desafios em uma estrutura de terminal.
- SWE: Eles extraem 32 mil prompts exclusivos de repositórios como SWE-bench e SWE-reBench. A parte inteligente? Este processo não requer um LLM “in the loop” para a adaptação inicial, tornando-o incrivelmente eficiente para dimensionar o volume.
2. Geração de Tarefas Sintéticas (A Camada Fina)
Para preencher a lacuna entre o raciocínio geral e os rigores específicos da agência de terminais, a equipe da NVIDIA usa Terminal-Tarefa-Gen para criar tarefas novas e executáveis.
- Geração baseada em sementes: O LLM usa computação científica existente ou problemas algorítmicos como “inspiração” para sintetizar novas tarefas. O agente é forçado a instalar pacotes, ler arquivos de entrada e gravar resultados – espelhando um fluxo de trabalho de desenvolvedor do mundo real.
- Geração baseada em habilidades: É aqui que a coisa fica técnica. A NVIDIA fez a curadoria de uma taxonomia de “habilidades terminais primitivas” em nove domínios, incluindo segurança, ciência de dados e administração de sistemas. O LLM é então instruído a combinar 3 a 5 dessas primitivas (como travessia de gráfico + configuração de rede + E/S de arquivo) em uma tarefa única e complexa.
Resolvendo as despesas gerais de infraestrutura
Um dos avanços de engenharia mais significativos nesta pesquisa é a mudança para Imagens Docker pré-construídas. As estruturas anteriores geralmente geravam um Dockerfile exclusivo para cada tarefa, levando a uma enorme sobrecarga no tempo de construção e a falhas frequentes. Em vez disso, a equipe da NVIDIA mantém nove imagens básicas compartilhadas pré-configuradas com bibliotecas essenciais (como pandas para ciência de dados ou ferramentas de criptografia para segurança). Este método de criação de ‘passagem única’ permite paralelização massiva e um consumo de recursos significativamente menor.
Desempenho: quando 32B supera 480B
Os resultados desta abordagem centrada em dados são surpreendentes. A equipe da NVIDIA usou esse pipeline para treinar o Terminal Nemotron família de modelos, inicializada a partir de Qwen3.
No Terminal-bancada 2.0 benchmark, que testa agentes em fluxos de trabalho ponta a ponta, como treinamento de modelos de aprendizado de máquina ou depuração de ambientes de sistema, as melhorias foram verticais:
- Nemotron-Terminal-8B: Saltou de uma taxa de sucesso de 2,5% para 13,0%.
- Nemotron-Terminal-32B: Conseguiu um 27,4% precisão.
Para colocar isso em perspectiva, o modelo 32B superou o Codificador 480B Qwen3 (23,9%) e rivalizou com o desempenho de gigantes de código fechado como Grok 4 (23,1%) e GPT-5-Mini (24,0%). Isso prova que, para agentes terminais, dados de trajetória diversificados e de alta qualidade são uma alavanca mais poderosa do que a simples escala de parâmetros.
Insights críticos
A pesquisa da NVIDIA também desmascara vários mitos comuns na engenharia de dados:
- Não filtre erros: A equipe de pesquisa descobriu que manter trajetórias “malsucedidas” nos dados de treinamento melhorou o desempenho (12,4% versus 5,06% para filtragem somente de sucesso). Expor modelos a estados de erro e padrões de recuperação realistas os torna mais robustos.
- Pule o currículo: Experimentaram a “aprendizagem curricular” (formação em dados fáceis antes de dados concretos), mas descobriram que a formação mista simples era igualmente eficaz, se não melhor.
- Limites de comprimento do contexto: Embora as trajetórias dos terminais possam ser longas, a maior parte da supervisão de alta qualidade se enquadra em uma janela padrão de 32.768 tokens. Estender a duração do contexto prejudicou ligeiramente o desempenho, provavelmente porque as trajetórias de cauda longa tendem a ser mais ruidosas.
Confira Papel e Página do projeto HF. Além disso, sinta-se à vontade para nos seguir no Twitter e não se esqueça de participar do nosso SubReddit de 120k + ML e inscreva-se em nosso boletim informativo. Espere! você está no telegrama? agora você também pode se juntar a nós no telegrama.
A postagem NVIDIA AI lança Nemotron-Terminal: um pipeline sistemático de engenharia de dados para dimensionar agentes de terminal LLM apareceu pela primeira vez em MarkTechPost.
Deseja saber mais sobre Inteligência Artificial, Clique Aqui!